The git directory acts as a database for all the changes tracked in Git and the working tree acts as a sandbox where we can edit the current version of the files
Staging Area(index)
A file maintained by Git that contains all of the information about what files and changes are going to go into your next commit
Any Git project will consist of 3 sections: Git directory, working tree, Staging area
After modifying a file, we need to stage those changes and then commit them afterwards
chmod +x all_check.py //makes the scripts excutable
A commit message is required, or the commit will be aborted
which command would we use to view pending changes? git status
to generate a patch to fix the current bug diff fix_permission.py fix_permissions_modified.py > fix_permission.patch
apply the patch to the file: patch fix_names.conf < fix_names.patch
the wdiff commandhighlights the words that changed in a file instead of working by line
A commit is a collection of edits which has been submitted to the version control system for safe keeping
Within a VCS, project files are organized in centralized locations called repositories where they can be called upon later
Git 常见命令
git add will add a file to the staging area and mark it for tracking
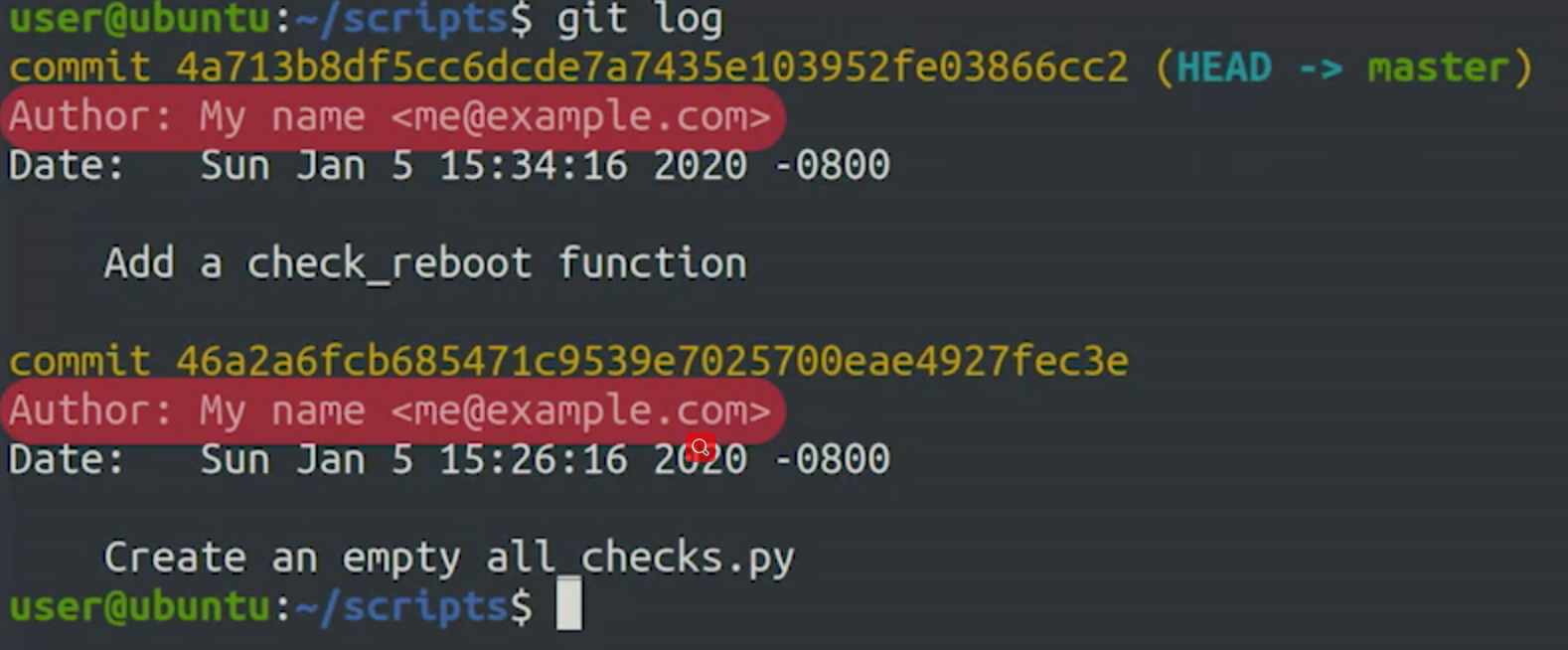
git log will give us information about the author of each commit, its timestamp, and each commit message
git config -l is used to check the current user configuration
git status is used to retrieve information about changes waiting to be committed
user@ubuntu: ~$ mkdir checks user@ubuntu: ~$ cd checks user@ubuntu: ~/checks$ git init Initialized empty Git repository in /home/user/checks/.git/
The area outside the git directory is the working tree. The working tree is the current version of your project.
add git
-m to pass the commit message user@ubuntu: ~/checks$ git commit -m 'Add periods to the end of sentences.'
anatomy of a Commit Message
short summary
detailed explaation
more infomation related to the message
git log : git log -p
git commit -a A shortcut to stage any changes to tracked files and commit them in one step git commit -a dosen’t work on new files
Can only write short message
user@ubuntu:~/scripts$ git commit -a -m "Call check_reboot from main, exit with 1 on error"
for truely small changes
Git uses the HEAD alias to represent the currently checked-out snapshot of your project.
This lets you know what the contents of your working directory should be.
user@ubuntu:~/scripts$ git add -p
#when using -p flag, git will show us the change being added and ask us if we want to stage it or not
1 2 3
user@ubuntu:~/scripts$ git diff #only unstaged changes by default
user@ubuntu:~/scripts$ git diff -staged #to see the changes that are staged but not committed
we can see the actual stage changes before we call git commit
You can remove files from your repository with the git rm command, which will stop the file from being tracked by git and remove it from the git directory
git checkout followed by the name of the file you want to revert.
git reset
We’ve added something to the staging area that we didn’t actually want to commit, we can unstage our changes by using git reset.
git add end up adding any change done in the working tree to the staing area
--amend git commit --amend overwirte the previous commit
Avoid amending commits that have already been made public
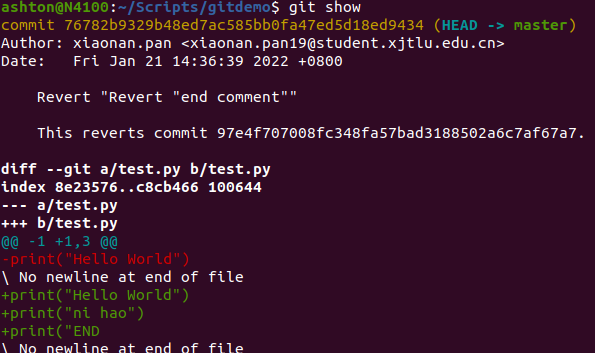
With git revert, a new commit is created with inverse changes. This cancels previous changes instead of making it as though the original commit never happened.
You can verify the data you get back out is the exact same data you put in
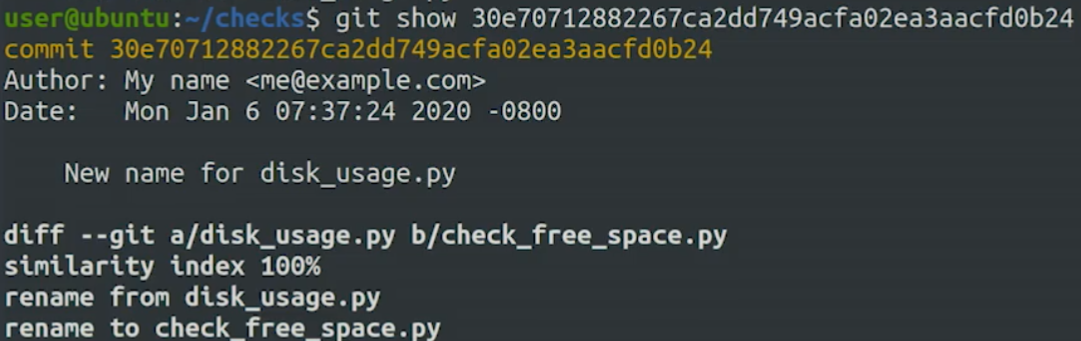
git show
help us easily view the log message and diff output the last commit if we don’t know the commit ID