渲染流水线基础概念
输入是一个虚拟摄像机、一些光源、一些Shader以及纹理等等。最终目的在于生成或者说是渲染一张二维纹理。
应用阶段(通常由CPU负责实现)、几何阶段、光栅化阶段
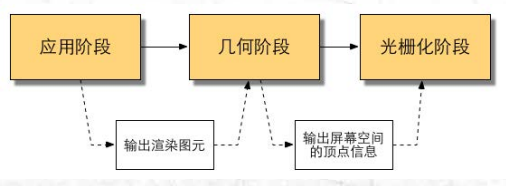
应用阶段
在这一阶段中, 开发者有3个主要任务: 首先, 我们需要准备好场景数据, 例如摄像机的位 置、 视锥体、 场景中包含了哪些模型、 使用了哪些光源等等;其次, 为了提高渲染性能, 我们往 往需要做一个粗粒度剔除(culling)工作, 以把那些不可见的物体剔除出去, 这样就不需要再移 交给几何阶段进行处理;最后, 我们需要设置好每个模型的渲染状态。这些渲染状态包括但不限于它使用的材质(漫反射颜色,高光反射颜色)、使用的纹理、使用的Shader等等。这一阶段最重要的输出是渲染所需要的几何信息,即渲染图元(rendering primitives)。通俗来讲,渲染图元可以是点、线、三角面等。这些渲染图元将会被传递给下一个阶段——几何阶段
把数据加载到显存中
设置渲染状态
调用 Draw Call
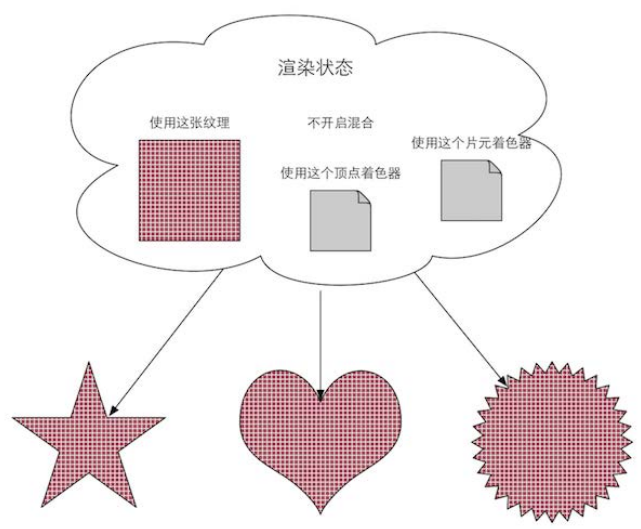
设置渲染状态
这些状态定义了场景中的网格是怎样被渲染的
例如, 使用哪个顶点着色器 (Vertex Shader) I片元着色器 (Fragment Shader)、 光源属性、材质等。 如果我们没有更改渲染状态, 那么所有的网格都将使用同一种渲染状态。 下图显示了当使用同 一种渲染状态时, 渲染 3 个不同网格的结果。在准备好上述所有工作后, CPU 就需要调用一个渲染命令来告诉GPU: “嘿!老兄, 我都帮 你把数据准备好啦, 你可以按照我的设置来开始渲染啦! ” 而这个渲染命令就是 Draw Call。
调用 Draw Call
相信接触过渲染优化的读者应该都听说过 Draw Call。 实际上, Draw Call 就是一个命令, 它 的发起方是 CPU, 接收方是GPU 。这个命令仅仅会指向一个需要被渲染的图元 (primitives) 列表, 而不会再包含任何材质信息-这是因为我们已经在上一个阶段中(设置渲染状态)完成了
当给定了一个 Draw Call 时, GPU 就会根据渲染状态(例如材质、 纹理、 若色器等)和所有 输入的顶点数据来进行计算, 最终输出成屏器上显示的那些漂亮的像素。 而这个计算过程, 就是 我们下一节要讲的GPU 流水线
几何阶段
几何阶段用于处理所有和我们要绘制的几何相关的事情。
例如,决定需要绘制的图元是什么, 怎样绘制它们,在哪里绘制它们。这一阶段通常在 GPU 上进行
几何阶段负责和每个渲染图元打交道,进行逐顶点、逐多边形的操作。这个阶段可以进一步 分成更小的流水线阶段 。几何阶段的一个重要任务就是把顶点坐标变换到屏幕空间中 ,再交给光栅器进行处理。通过对输入的渲染图元进行多步处理后,这一阶段将会输出屏幕空间的二维顶点坐标、每个顶点对应的深度值、着色等相关信息,并传递给下一个阶段。
光栅化阶段
此阶段将会使用上个阶段传递的数据来产生屏幕上的像素,并渲染出最终的图像。这 段也是在 GPU 上运行 。光栅化的任务主要是决定每个渲染图元中 的哪些像素应该被绘制在屏幕上。它需要对上一个阶段得到的逐顶点数据 (例如纹理坐标 、顶点颜色等)进行插值,然后再进行逐像素处理。
GPU 流水线
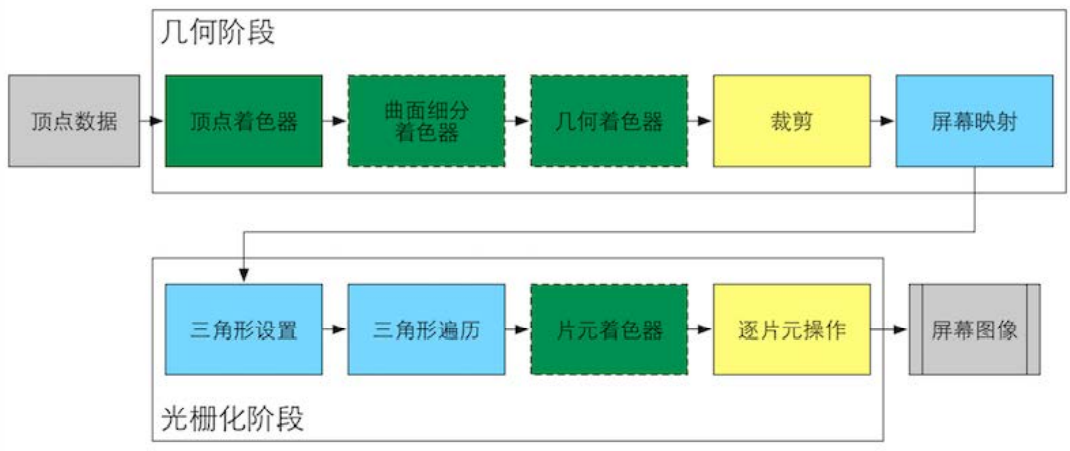
颜色表示了不同阶段的可配置性或可编程性:绿色表示该流水线阶段是完全可编程控制的,黄色表示该流水线阶段可以配置但不是可编程的,蓝色表示该流水线阶段是由 GPU 固定实现的,开发者没有任何控制权。实线表示该 Shader 必须由开发者编程实现,虚线表示该 Shader 是可选的
GPU 的渲染流水线接收顶点数据作为输入。
几何阶段
顶点着色器 (Vertex Shader) 是完全可编程的,它通常用千实现顶点的空间变换、顶点着色等功能。
曲面细分着色器 (Tessellation Shader) 是一个可选的着色器,它用于细分图元。
几何着 色器 (Geometry Shader) 同样是一个可选的着色器,它可以被用于执行逐图元(Per-Primitive) 的着色操作,或者被用于产生更多的图元。
下一个流水线阶段是裁剪 (Clipping), 这一阶段的目的是将那些不在摄像机视野内的顶点裁剪掉,并剔除某些三角图元的面片。这个阶段是可配置的。 例如,我们可以使用自定义的裁剪平面来配置裁剪区域,也可以通过指令控制裁剪三角图元的正 面还是背面。
几何概念阶段的最后一个流水线阶段是屏幕映射 (Screen Mapping) 。此阶段是不可配置和编程的,它负责把每个图元的坐标转换到屏幕坐标系中。
顶点着色器 Vertex Shader
顶点着色器的处理单位是顶点,也就是说,输入进来的每个顶点都会调用一次顶点着色器。
顶点着色器本身不可以创建或者销毁任何顶点,而且无法得到顶点与顶点之间的关系。例如,我们无法得知两个顶 点是否属千同一个三角网格。但正是因为这样的相互独立性,GPU 可以利用本身的特性并行化处理每一个顶点,这意味着这一阶段的处理速度会很快。
顶点着色器需要完成的工作主要有:坐标变换和逐顶点光照。当然,除了这两个主要任务外, 顶点着色器还可以输出后续阶段所需的数据。下图展示了在顶点着色器中对顶点位置进行坐标变换并计算顶点颜色的过程。
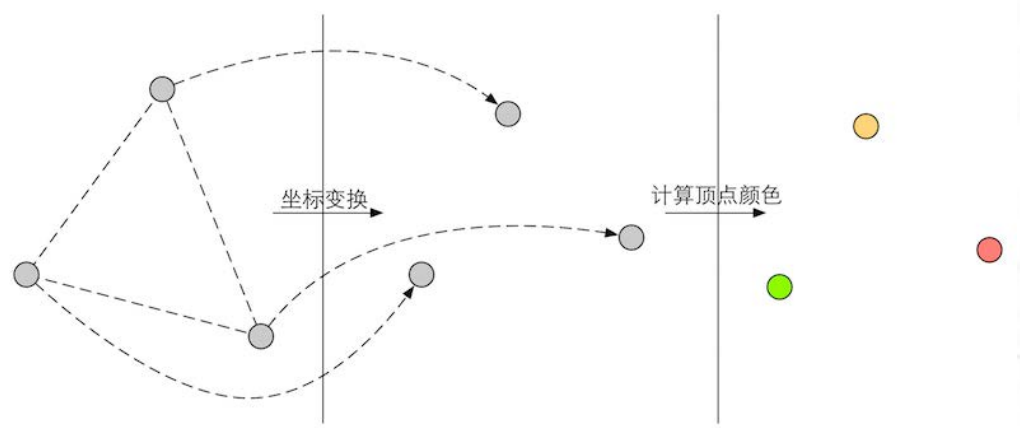
坐标变换。顾名思义,就是对顶点的坐标(即位置)进行某种变换。顶点着色器可以在这 一步中改变顶点的位置,这在顶点动画中是非常有用的。例如,我们可以通过改变顶点位置来模拟水面、布料等。但需要注意的是无论我们在顶点着色器中怎样改变顶点的位置,一个最基本的顶点着色器必须完成的一个工作是,把顶点坐标从模型空间转换到齐次裁剪空间 。想想看,我们在顶点着色器中是不是会看到类似下面的代码
1 | o.pos = mul(UNITY_MVP, v.position); |
类似上面这句代码的功能,就是把顶点坐标转换到齐次裁剪坐标系下,接着通常再由硬件做透视除法后,最终得到归一化的设备坐标 (Normalized Device Coordinates , NDC)
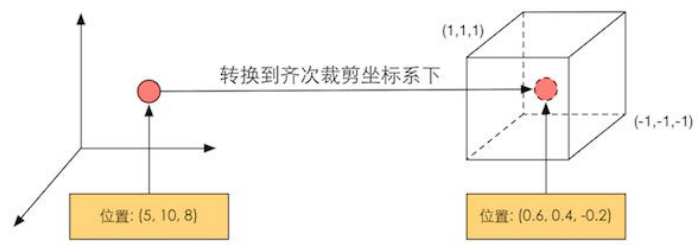
需要注意的是,上图给出的坐标范围是 OpenGL 同时也是 Unity 使用的 NDC, 它的 ${z}$ 分量 范围在[-1,1] 之间,而在 DirectX 中, NDC 分量范围是 [0, 1] 。顶点着色器可 以有不同的输出方式。最常见的输出路径是经光栅化后交给片元着色器进行处理。而在现代的 Shader Model 它还可以把数据发送给曲面细分着色器或几何着色器。
裁剪 Clipping
由于我们的场景可能会很大 ,而摄像机的视野范围很有可能不会覆盖所有的场景物体, 一个很自然的想法就是,那些不在摄像机视野范围的物体不需要被处理 。而裁剪 (Clipping) 就是为 了完成这个目的而被提出来的。
一个图元和摄像机视野的关系有完全在视野内、部分在视野内、完全在视野外。完全在视野内的图元就继续传递给下一个流水线阶段,完全在视野外的图元不会继续向下传递,因为它们不需要被渲染。而那些部分在视野内的图元需要进行一个处理,这就是裁剪。例如 ,一条线段的一个顶点在视野内 ,而另一个顶点不在视野内,那么在视野外部的顶点应该使用一个新的顶点来代替,这个新的顶点位于这条线段和视野边界的交点处。
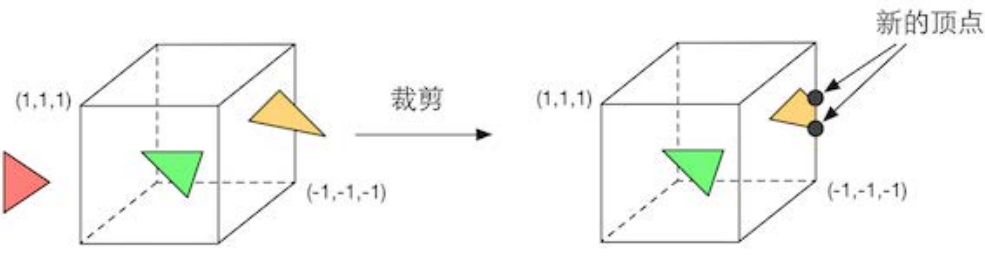
和顶点着色器不同,这一步是不可编程的,即我们无法通过编程来控制裁剪的过程,而是硬件上的固定操作,但我们可以自定义一个裁剪操作来对这一步进行配置。
屏幕映射 Screen Mapping
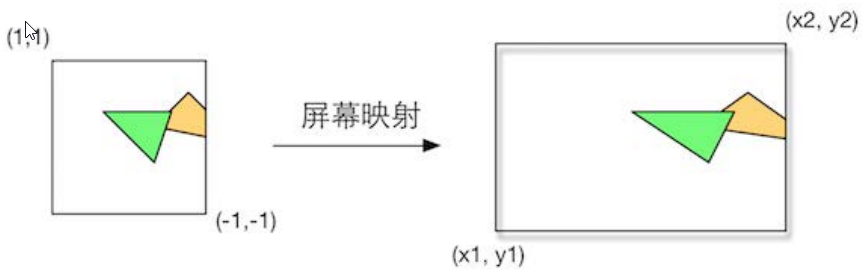
这一步输入的坐标仍然是三维坐标系下的坐标(范围在单位立方体内)。屏幕映射 (Screen Mapping) 的任务是把每个图元的坐标转换到 屏幕坐标系 (Screen Coordinates) 下。屏幕坐标系是一个二维坐标系,它和我们用于显示画面的分辨率有很大关系。
假设,我们需要把场景渲染到一个窗口上,窗口的范围是从最小的窗口坐标${(x_1,y_1)}$到最大的窗口坐标${(x_2,y_2)}$, 其中${x_1<x_2}$且${y_1 < y_2}$。由于我们输入的坐标范围在-1 到1, 因此可以想象到,这个过程实际是一个缩放的过程,如下图所示。你可能会问,那么输入的 ${z}$ 坐标会怎么样呢?屏幕映射不会对输入的 ${z}$ 坐标做任何处理。
实际上,屏幕坐标系和${z}$坐标一起构成了一个坐标系,叫窗口坐标系 (Window Coordinates) 。这些值会一起被传递到光栅化阶段
屏幕映射得到的屏幕坐标决定了这个顶点对应屏幕上哪个像素以及距离这个像素有多远。
光栅化阶段
光栅化概念阶段中的三角形设置 (Triangle Setup) 和三角形遍历 (Triangle Traversal) 阶段也都是固定函数 (Fixed-Function) 的阶段。接下来的片元着色器 (Fragment Shader), 则是完全可编程的,它用于实现逐片元 Per-Fragment 的着色操作。最后,逐片元操作 (Per-Fragment Operations) 阶段负责执行很多重要的操作,例如修改颜色、深度缓冲、进行混合等,它不是可编程的,但具有很高的可配置性。
三角形设置 Triangle Setup
由这一步开始就进入了光栅化阶段。从上一个阶段输出的信息是屏幕坐标系下的顶点位置以及和它相关的额外信息,如深度值 (z 坐标)、法线方向、视角方向等。光栅化阶段有两个最重要的目标:计算每个图元覆盖了哪些像素,以及为这些像素计算它们的颜色。
光栅化的第一个流水线阶段是三角形设置 (Triangle Setup) 。这个阶段会计算光栅化一个三角网格所需的信息。具体来说,上一个阶段输出的都是三角网格的顶点,即我们得到的是三角网格每条边的两个端点。但如果要得到整个三角网格对像素的覆盖情况我们就必须计算每条边上 的像素坐标。为了能够计算边界像素的坐标信息,我们就需要得到三角形边界的表示方式。这样一个计算三角网格表示数据的过程就叫做三角形设置。它的输出是为了给下一个阶段做准备。
三角形遍历 Triangle Traversal
三角形遍历 (Triangle Traversal) 阶段将会检查每个像素是否被一个三角网格所覆盖。如果被覆盖的话,就会生成一个片元 (fragment) 。而这样一个找到哪些像素被三角网格覆盖的过程就是三角形遍历,这个阶段也被称为扫描变换 (Scan Conversion)
三角形遍历阶段会根据上一个阶段的计算结果来判断一个三角网格覆盖了哪些像素,并使用三角网格3个顶点的顶点信息对整个覆盖区域的像素进行插值。下图展示了三角形遍历阶段的简化计算过程。
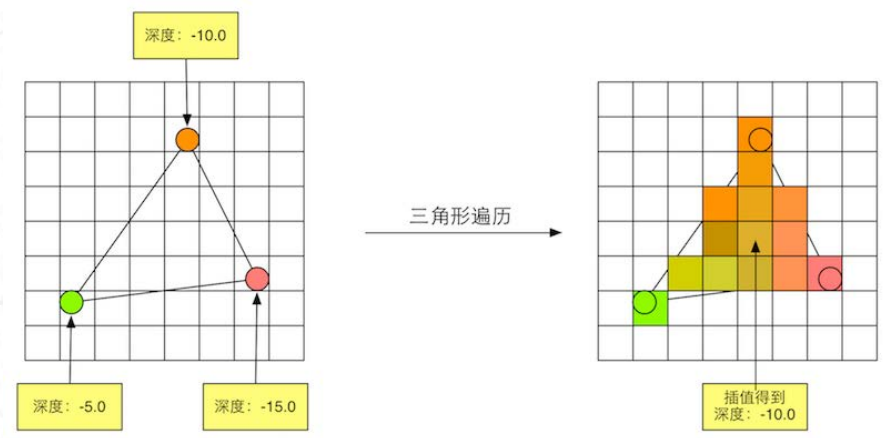
这一步的输出就是得到一个片元序列。需要注意的是,一个片元并不是真正意义上的像素,而是包含了很多状态的集合,这些状态用于计算每个像素的最终颜色。这些状态包括了(但不限于)它的屏幕坐标深度信息,以及其他从几何阶段输出的顶点信息,例如法线、纹理坐标等。
片元着色器 Fragment Shader
片元着色器 (Fragment Shader) 是另一个非常重要的可编程着色器阶段。在 DirectX 中,片元着色器被称为像素着色器 (Pixel Shader), 但片元着色器是一个更合适的名字,因为此时的片元并不是一个真正意义上的像素。
前面的光栅化阶段实际上并不会影响屏幕上每个像素的颜色值,而是会产生一系列的数据信息,用来表述一个三角网格是怎样覆盖每个像素的。而每个片元就负责存储这样一系列数据。真正会对像素产生影响的阶段是下一个流水线阶段——逐片元操作 (Per-Fragment Operations) 我们随后就会讲到。、
片元着色器的输入是上一个阶段对顶点信息插值得到的结果。更具体来说,是根据那些从顶点着色器中输出的数据插值得到的。而它的输出是一个或者多个颜色值。
这一阶段可以完成很多重要的渲染技术,其中最重要的技术之一就是纹理采样。为了在片元着色器中进行纹理采样,我们通常会在顶点着色器阶段输出每个顶点对应的纹理坐标,然后经过光栅化阶段对三角网格的3个顶点对应的纹理坐标进行插值后,就可以得到其覆盖的片元的纹理
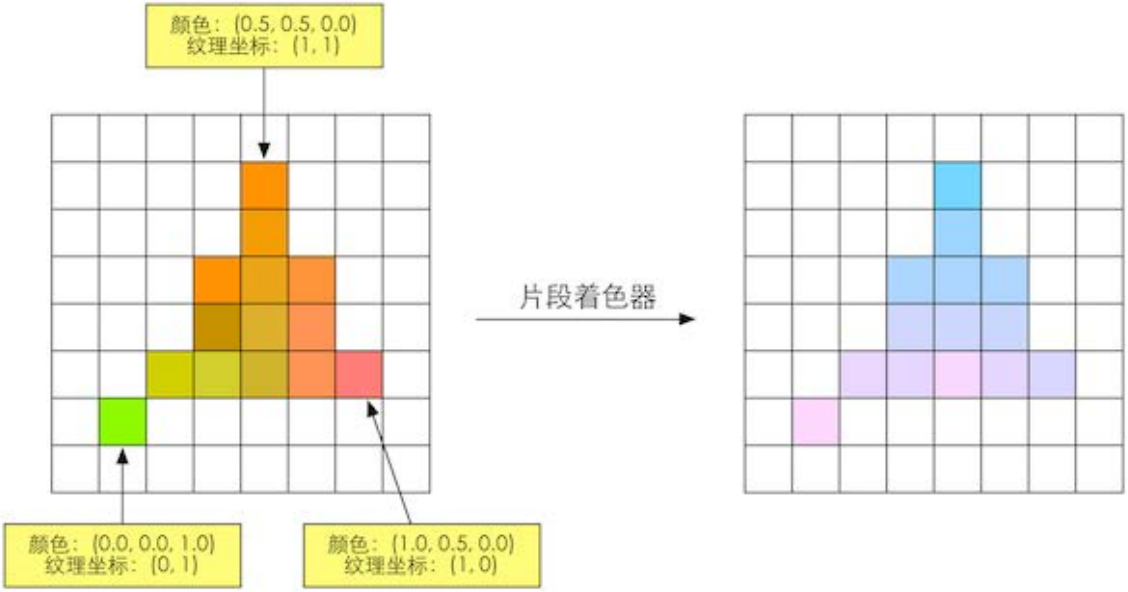
虽然片元着色器可以完成很多重要效果 但它的局限在于,它仅可以影响单个片元。也就是说,当执行片元着色器时,它不可以将自己的任何结果直接发送给它的邻居们。有一个情况例外, 就是片元着色器可以访问到导数信息 (gradient 或者说是 derivative) 。
逐片元操作 Per Fragment Operations
逐片元操作 (Per Fragment Operations) OpenGL 中的说法,在DirectX中,这一阶段被称为输出合井阶段 (Output-Merger) Merger 这个词可能更容易让读者明白这一步骤的目的:合并。而 OpenGL 中的名字可以让读者明白这个阶段的操作单位, 即是对每一个片元进行一些操作。那么问题来了,要合并哪些数据?又要进行哪些操作呢?
这一阶段有几个主要任务
- 决定每个片元的可见性。这涉及了很多测试工作,例如深度测试、模板测试等。
- 如果一个片元通过了所有的测试,就需要把这个片元的颜色值和已经存储在颜色缓冲区中的颜色进行合并,或者说是混合。
需要指明的是,逐片元操作阶段是高度可配置性的,即我们可以设置每一步的操作细节 。
这个阶段首先需要解决每个片元的可见性问题。这需要进行一系列测试。这就好比考试, 一个片元只有通过了所有的考试,才能最终获得和 GPU 谈判的资格,这个资格指的是它可以和颜色缓冲区进行合并。如果它没有通过其中的某一个测试,那么对不起,之前为了产生这个片元所做的所有工作都是白费的,因为这个片元会被舍弃掉。 Poor fragment! 下图给出了简化后的逐片元操作所做的操作。

作为一个想充分提高性能的 GPU, 它会希望尽可能早地知道哪些片元是会被舍弃的,对于这些片元就不需要再使用片元着色器来计算它们的颜色。 在 Unity 给出的渲染流水线中, 我们也可以发现它给出的深度测试是在片元着色器之前。这种将深度测试提前执行的技术通常也被称为Early-Z技术。
但是,如果将这些测试提前的话, 其检验结果可能会与片元着色器中的一些操作冲突。 例如,如果我们在片元着色器进行了透明度测试,而这个片元没有通过透明度测试, 我们会在着色器中调用 APJ C例如 clip 函数)来手动将其舍弃掉。 这就导致 GPU 无法提前执行各种测试。 因此,现代的 GPU 会判断片元着色器中的操作是否和提前测试发生冲突,如果有冲突,就会禁用提前测试。但是, 这样也会造成性能上的下降, 因为有更多片元需要被处理了。 这也是透明度测试会导致性能下降的原因。
现在大多数 GPU 都支持一种称为提前深度测试(Early depth testing)的硬件功能。提前深度测试允许深度测试在片段着色器之前运行。明确一个片段永远不会可见的 (它是其它物体的后面) 我们可以更早地放弃该片段。
片段着色器通常是相当费时的所以我们应该尽量避免运行它们。对片段着色器提前深度测试一个限制是,你不应该写入片段的深度值。如果片段着色器将写入其深度值,提前深度测试是不可能的,OpenGL不能事先知道深度值。
当模型的图元经过了上而层层计算和测试后, 就会显示到我们的屏幕上。 我们的屏幕显示的 就是颜色缓冲区中的颜色值。 但是,为了避免我们看到那些正在进行光栅化的图元,GPU 会使用双重缓冲 (Double Buffering) 的策略。这意味着,对场景的渲染是在幕后发生的, 即在后置缓冲 (Back Buffer) 中。 一旦场景已经被渲染到了后置缓冲中, GPU 就会交换后置缓冲区和前置缓冲 (Front Buffer) 中的内容, 而前置缓冲区是之前显示在屏幕上的图像。 由此, 保证了我们看到的图像总是连续的。
总结与常识
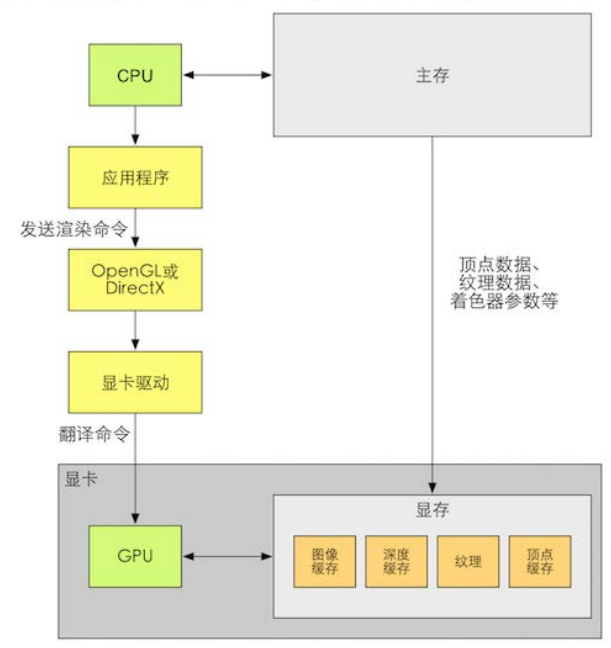
概括来说,我们的应用程序运行在 CPU 上。应用程序可以通过调用 OpenGL DirectX 的图形接口将渲染所需的数据,如顶点数据、纹理数据、材质参数等数据存储在显存中的特定区域 随后,开发者可以通过图像编程接口发出渲染命令,这些渲染命令也被称为 Draw Call, 它们将会 被显卡驱动翻译成 GPU 能够理解的代码,进行真正的绘制。
下图可以看出, 一个显卡除了有图像处理单元 GPU 外,还拥有自己的内存,这个内存通常被称为显存 (Video Random Access Memory, VRAM) GPU 可以在显存中存储任何数据, 但对于渲染来说一些数据类型是必需的,例如用于屏幕显示的图像缓冲、深度缓冲等。
投影
不管是透视投影(Perspective Projection)摄像机还是正交投影(Orthographic Projection)摄像机,视锥体都是由Top、Bottom、Right、Left以及Near和Far共六个平面组成。
利用投影的方法将顶点坐标从3D转变为2D:
首先将顶点的x、y、z坐标分别除以w分量(写给大家看的“透视除法” —— 齐次坐标和投影https://www.jianshu.com/p/7e701d7bfd79),得到标准化的设备坐标(Normalized Device Coordinate。NDC)。
空间变换流程图与变换矩阵
模型空间(本地空间) —模型变换(利用模型变换矩阵)—>世界空间 —视变换(利用视变换举证)—> 摄像机空间(观察空间)—投影变换(利用裁切矩阵)—>裁切空间 —屏幕投影(利用投影矩阵)—> 屏幕空间(得到屏幕像素坐标)
Shader和材质的关系与区别
Shader 实际上就是一段程序,它负责把输入的顶点数据按照代码里指定的方式进行处理,并对输入的颜色或者贴图等进行计算,然后输出数据。图像绘制单元获取到输出的数据便可将图像绘制出来,最终呈现在屏幕上。
Shader 程序代码,再加上开放的参数设置以及关联的贴图等等,为实现某种效果而打包存储在一起,最终得到的就是材质(Material)。
材质是Shader的实例化资源,一个Shader可以实例化为多个材质,并且调节为不同的材质效果。最后把材质指定给某个模型就可以渲染出对应的效果了。
Draw Call
Draw Call 本身的含义很简单,就是CPU 调用图像编程接口,如 OpenGL 中的 glDrawElements 命令或者 DirectX 中的 DrawlndexedPrimitive ,以命令 GPU 进行渲染的操作。
为什么 Draw Call 多了会影响帧率?
在每次调用 Draw Call 之前, CPU 需要向 GPU 发送很多内容,包括数据、状态和命令等。在这一阶段, CPU 需要完成很多工作,例如检查渲染状态等。而一旦 CPU 完成了这些准备工作, GPU 就可以开始本次的渲染。 GPU 的渲染能力是很强的,渲染 200 个还是 2 000个三角网格通常没有什么区别,因此渲染速度往往快于 CPU 提交命令的速度。如果 Draw Call 的数量太多, CPU 就会把大量时间花费在提交 Draw Call 上,造成 CPU 的过载。下图显示了这样一个例子:
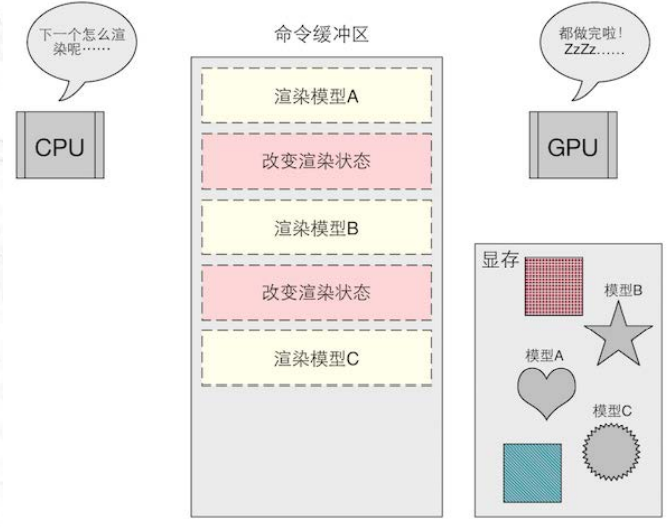
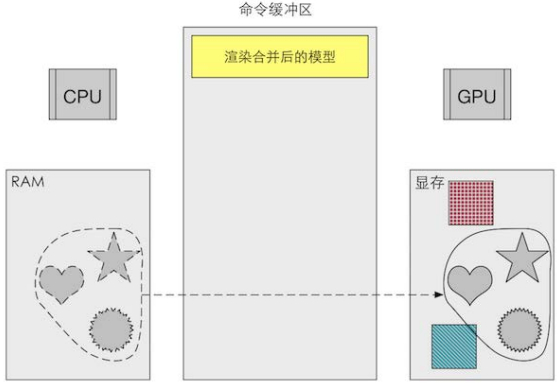
尽管减少 Draw Call 的方法有很多,但我们这里仅讨论使用批处理 (Batching) 的方法。 我们讲过,提交大量很小的 Draw Call 会造成 CPU 的性能瓶颈,即 CPU 把时间都花费在准 Draw Call 的工作上了 。那么,一个很显然的优化想法就是把很多小的 DrawCall 合并成一个大 Draw Call, 这就是批处理的思想。图 2.21 显示了批处理所做的工作。
如何减少 Draw Call?
尽管减少 Draw Call 的方法有很多,但我们这里仅讨论使用批处理 (Batching) 的方法。我们讲过,提交大量很小的 Draw Call 会造成 CPU 的性能瓶颈,即 CPU 把时间都花费在准备 Draw Call 的工作上了。那么,一个很显然的优化想法就是把很多小的 DrawCall 合并成一个大的 Draw Call, 这就是批处理的思想。
需要注意的是,由于我们需要在 CPU 的内存中合并网格,而合并的过程是需要消耗时间的。 因此,批处理技术更加适合于那些静态的物体,例如不会移动的大地、石头等,对于这些静态物体我们只需要合并一次即可。当然,我们也可以对动态物体进行批处理。但是,由于这些物体是不断运动的,因此每一帧都需要重新进行合并然后再发送给 GPU, 这对空间和时间都会造成一定的影响。
在游戏开发过程中,为了减少 Draw Call 的开销,有两点需要注意。
- 避免使用大蜇很小的网格。当不可避免地需要使用很小的网格结构时,考虑是否可以合并它们
- 避免使用过多的材质。尽量在不同的网格之间共用同一个材质。
固定管线渲染
固定函数的流水线 (Fixed-Function Pipeline), 也简称为固定管线,通常是指在较旧的 GPU 上实现的渲染流水线。这种流水线只给开发者提供一些配置操作,但开发者没有对流水线阶段的完全控制权。
固定管线通常提供了一系列接口,这些接口包含了一个函数入口点 (Function Entry Points) 集合,这些函数入口点会匹配 GPU 上的一个特定的逻辑功能。开发者们通过这些接口来控制渲染流水线。换句话说,固定渲染管线是只可配置的管线。一个形象的比喻是,我们在使用固定管线进行渲染时,就好像在控制电路上的多个开关,我们可以选择打开或者关闭一个开关,但永远无法控制整个电路的排布。
简化的渲染完整流水线
建立场景
- 在真正开始渲染之前,需要对整个场景进行预先设置,例如:摄像机视角、灯光设置以及物化设置等等。
可见性检测
- 有了摄像机,就可以基于摄像机视角检测场景中所有物体的可见性。这一步在实时渲染中极为重要,因为可以避免把时间和性能浪费在渲染一些视角之外的物体上。
设置渲染状态
- 一旦检测到某个物体是可见的,接下来就需要把它绘制出来了。但是由于不同物体的渲染状态可能不同(如何进行深度测试、如何与背景图像进行混合等),因此在开始渲染该物体之前首先需要设置该物体的渲染状态。
几何体生成与提交
- 接着,就需要向渲染API提交几何体数据了,一般所提交的数据为三角形的顶点数据。例如:顶点坐标、法线向量、UV等。
变换与光照
- 当渲染API获取到三角形顶点数据之后,就需要将顶点坐标从模型空间变换到摄像机空间,并且同时进行顶点光照计算。
背面剔除与裁切
- 变换到摄像机空间之后,那些背对着摄像机的三角形会被剔除,然后再被变换到裁切空间中,将视锥体之外的部分裁切掉。
投影到屏幕空间
- 在裁切空间中经历裁切之后的多边形会通过投影从三维变为平面,输出到屏幕空间中。
光栅化
- 屏幕空间中的几何体还需要经过光栅化处理才能转变为2D的像素信息。
像素着色 nm
- 最后,计算每个像素的颜色,并把这些颜色信息输出到屏幕上。